Gemini 3가 출시했는데.. 어떻게 볼까요?


지난 11월 18일, Gemini 3가 출시하여 사람들의 많은 주목을 받고 있습니다.
이렇게 종종 새로운 버전의 AI가 출시되면 대부분 정량적인 지표를 가져와서 사람들에게 이 AI가 얼마나 좋은 AI인지 홍보하곤 하는데요.
여기서 문득 필자는 이런 생각이 들게 됩니다.
정량적인 평가는 모든 공평한 조건 속에서 진행해도 결국 서로 비슷한 실력이라면 어떤 변수에 따라 등수가 손바닥 뒤집듯이 바뀔 수 있지 않는가?
그래서 이번엔 객관적인 정량적인 수치로 어떻게 AI들을 비교하는지, 그리고 Gemini 3의 성능이 어디서 얼마나 좋은지 알아봅시다.
평가 기준에 관한 문서
다행히도, 공식 블로그에서 이런 평가 기준에 대한 pdf를 제공해주어서, 쉽게 참고할만한 사이트들을 알려주었습니다. 그 중 몇몇 나열해준 사이트들이 있는데요.

실제로 Google Deepmind에서 공식 API를 사용했다는 사이트들을 한번 각각 살펴봅시다.
먼저 알면 좋은 용어: 제로샷
이 벤치마크에 대해 설명을 보다보니 가장 빈번하게 나오는 용어가 하나 있어 이 용어를 이야기해보고자 합니다.
바로 제로샷(zero-shot)인데요.
이 용어는 AI가 사전에 데이터를 학습하지 않은 상태로 새로운 작업을 수행하는 방법입니다.
그래서 AI의 성능을 파악할 때, 보통 객관적인 평가 점수를 만들기 위해 적용하지만, 프롬프트 엔지니어링을 한다면 AI의 성능이 프롬프트에 크게 의존하게 되므로 프롬프트 설계 시 주의하라고 합니다.
그러면 본격적으로 살펴봅시다.
멀티모달 이해 벤치마크
이미지, 텍스트, 차트 등 다양한 데이터를 얼마나 잘 이해하는지 측정합니다.
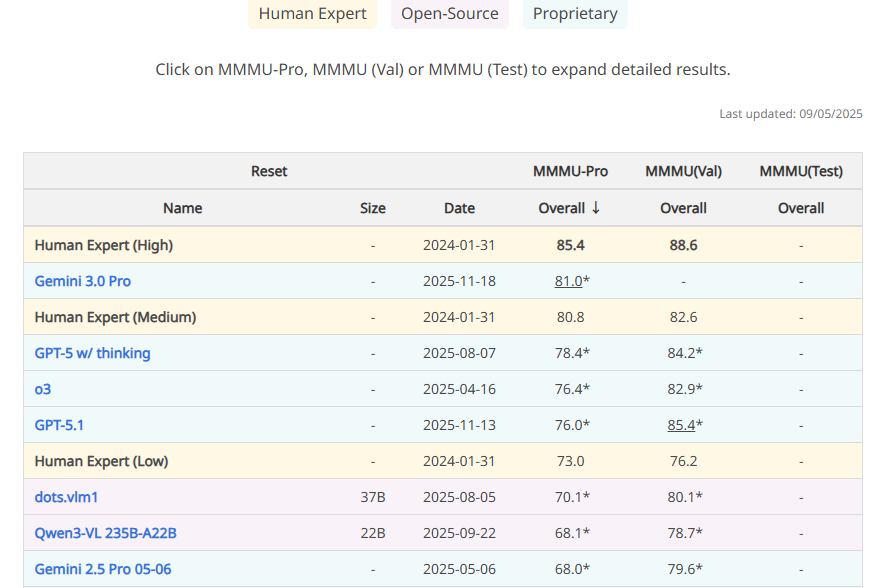
MMMU
MMMU(Massive Multi-discipline Multimodal Understanding and Reasoning)는 전문가 수준의 여럿 광범위한 분야에서 AI가 어느정도 이해하는지 평가합니다.
평가 방법:
- 데이터: 11,500개 질문
- 분야: 예술, 비즈니스, 과학, 공학, 의약학, 사회학
- 이미지: 차트, 다이어그램, 지도, 악보 등
- 측정: 지각, 지식, 추론 능력
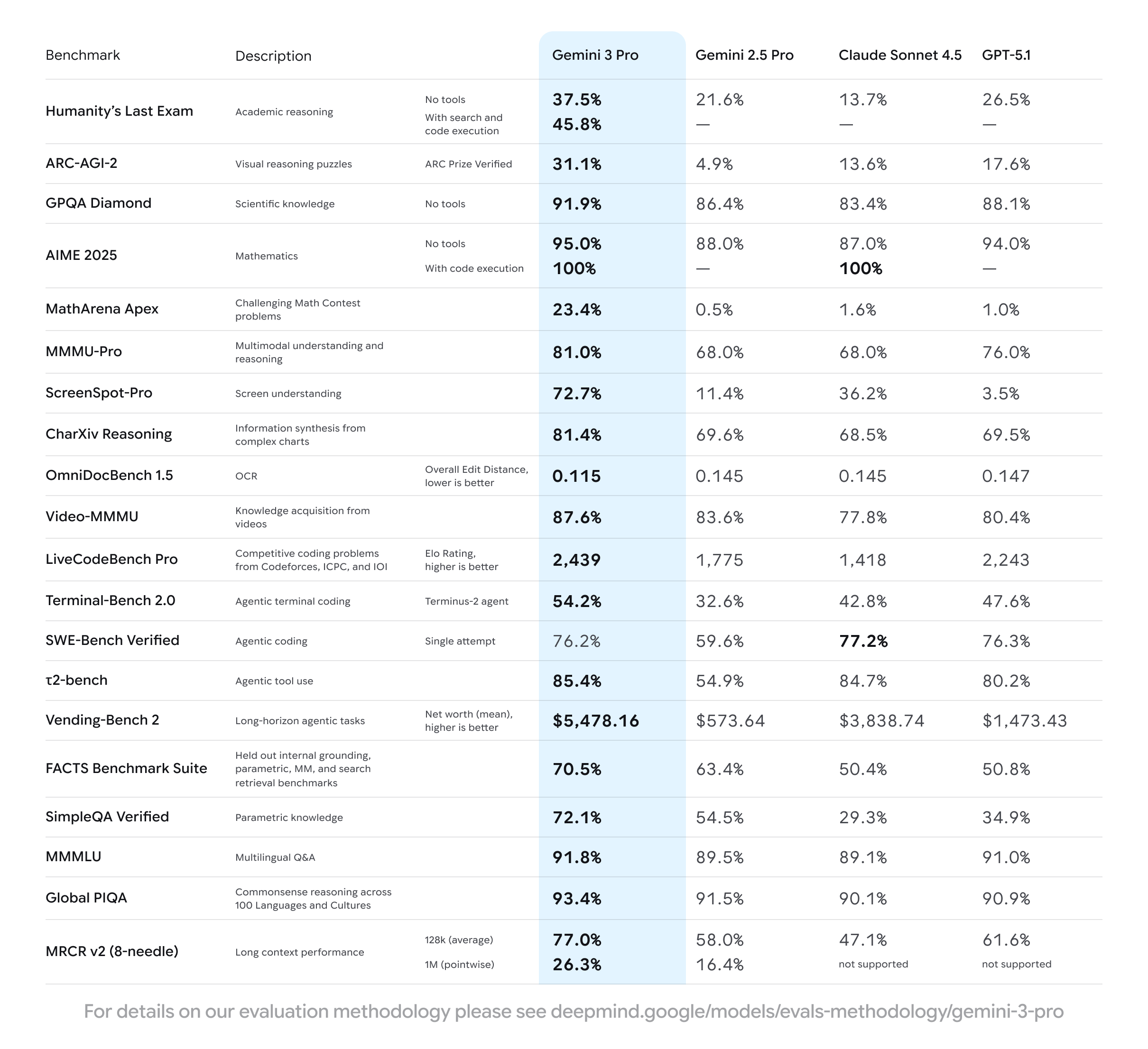
Gemini 3 성능:
- 전체 AI 중 1위
- 정확한 수치는 아직 미공개
ScreenSpot-Pro
측정 대상: 앱이나 웹 UI의 구조, 레이블, 맥락 이해도를 측정합니다.
평가 방법:
- 데이터: 다양한 앱/웹 인터페이스 화면
- 측정: UI 요소의 위치, 기능, 관계 식별 정확도
Gemini 3 성능:
- 72.7% 정확도
- 다른 모델 대비 +15%p
OmniDocBench
측정 대상: 스캔 문서나 이미지에서 글자를 읽고 레이아웃을 고려해 텍스트를 복원하는 능력을 측정합니다.
평가 방법:
- 데이터: 다양한 스캔 문서 및 이미지
- 측정: OCR + 레이아웃 이해, Edit Distance로 측정 (짧을수록 우수)
Gemini 3 성능:
- 다른 모델 대비 오류 80% 감소
추론 능력 벤치마크
정보를 인식하는 것을 넘어 논리적으로 사고하는 능력을 측정합니다.
CharXiv Reasoning
측정 대상: 그래프를 현실적으로 이해하고 해석하는 능력을 측정합니다.
평가 방법:
- 데이터: 전문가가 선정한 실제 그래프
- 목적: AI의 과도한 낙관적 해석 경향 개선
- 측정: 그래프 의미를 정확하고 현실적으로 파악하는지 평가
Gemini 3 성능:
- 81.4% 정확도
- 다른 모델(~70%) 대비 +11%p
Video-MMMU
측정 대상: 교육 비디오에서 지식을 습득하고 이해하는 능력을 평가합니다.
평가 방법:
- 데이터: 6개 분야, 30개 과목, 300개 대학 수준 강의
- 측정: 지각, 이해, 적응 세 단계로 평가
- 추가: 영상 학습 후 AI 자체 성능 향상도 측정
Gemini 3 성능:
- 다른 모델 대비 +10% 향상
언어 이해 벤치마크
다양한 언어와 문화에서 AI가 보편적으로 작동하는지 평가합니다.
MMMLU
측정 대상: 일반 지식에 대한 다국어 이해도를 평가하는 표준 벤치마크입니다.
평가 방법:
- 데이터: 57개 범주의 광범위한 주제
- 범위: 초급 지식부터 법, 물리, 역사, 컴퓨터 과학까지
- 언어: 전문 번역가가 14개 언어로 번역
- 측정: 다국어 환경에서의 지식 이해도
Gemini 3 성능:
- 다른 모델 대비 +1%
Global PIQA
측정 대상: 각 문화권의 상식과 맥락 이해도를 평가합니다.
평가 방법:
- 데이터: 100개 이상 언어
- 제작: 300명 이상 전문가가 수작업 구축
- 측정: 문화적 맥락을 고려한 추론 정확도
Gemini 3 성능:
- 다른 모델 대비 +2%
마무리
이렇게 해서 Gemini 3 출시 기념으로 구글 블로그에서 알려준 AI의 벤치마크들을 살펴보았습니다.
확실히 다른 AI들에 비해 언어, 문화 부분에서 소폭 상승한 것 제외하고 다른 분야에서 성능적으로 좋다는 것을 알게 되었는데요.
많은 개발 분야 중에서 아직은 사람들의 수작업이 필요한 부분이 AI 벤치마크가 아닐까 싶습니다.
그리고 AI 벤치마크 관련 문서들을 읽어보며 깨달은 것은, 인간이였으면 바로바로 나올 값들도 AI가 스스로 의사결정하면 랜덤한 확률로 인간의 범주에 벗어난 생각들을 할 수 있겠다 싶었습니다.
당장 인간인 우리도 하나의 책을 읽으면 서로 생각하는 것이 다르듯이 말이죠.
위에 제가 작성한 것들 외에도 수많은 AI 성능 체크를 위한 벤치마크들이 많이 있으므로, 혹시 관심이 있다면 살펴보는 것을 추천드립니다.