블로그 검색기능 넣는데 12시간 걸린 이야기

최근 블로그 글감으로 다시 한번 큐레이션 글을 보자는 생각이 들어서 글또 블로그에 들어갔다.
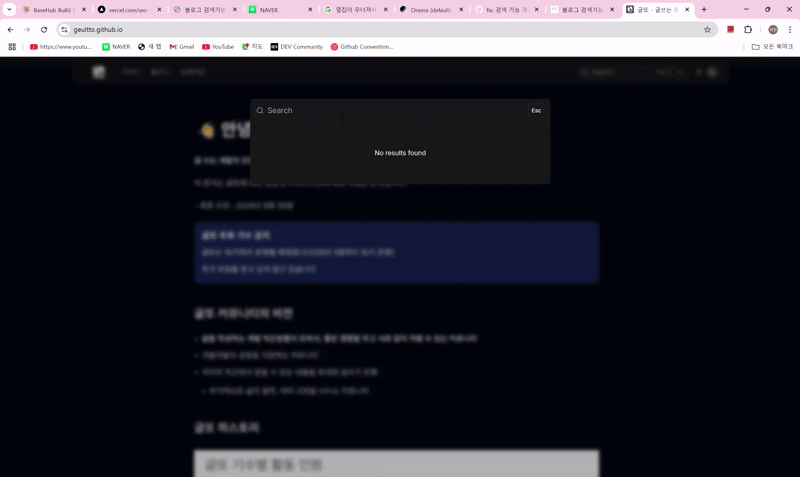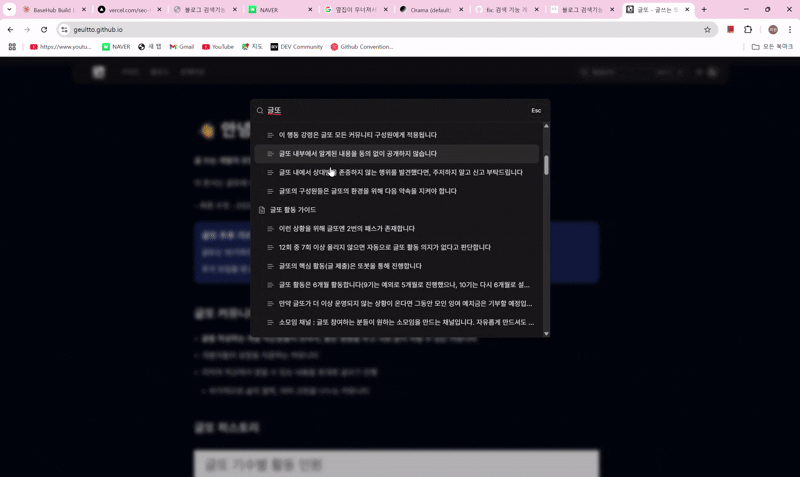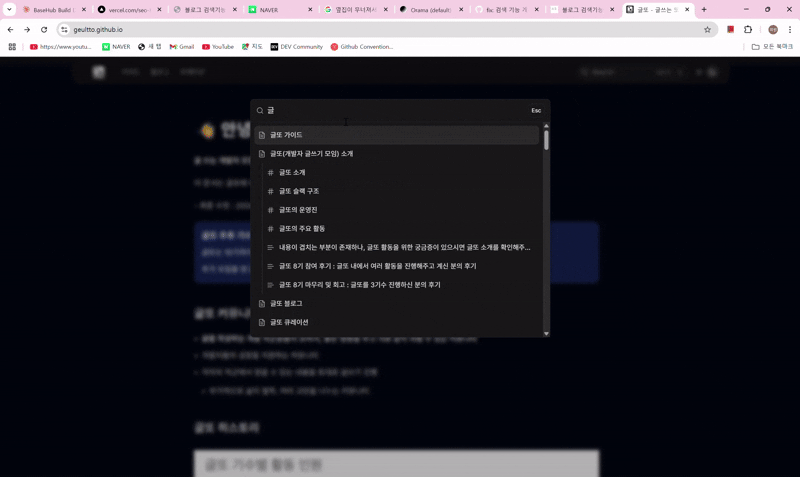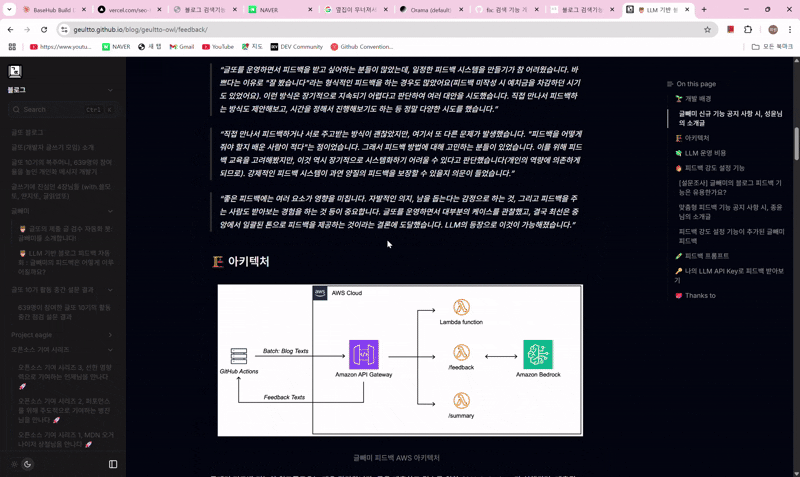
현재 글또 블로그의 검색 기능은 매우 잘 됩니다.
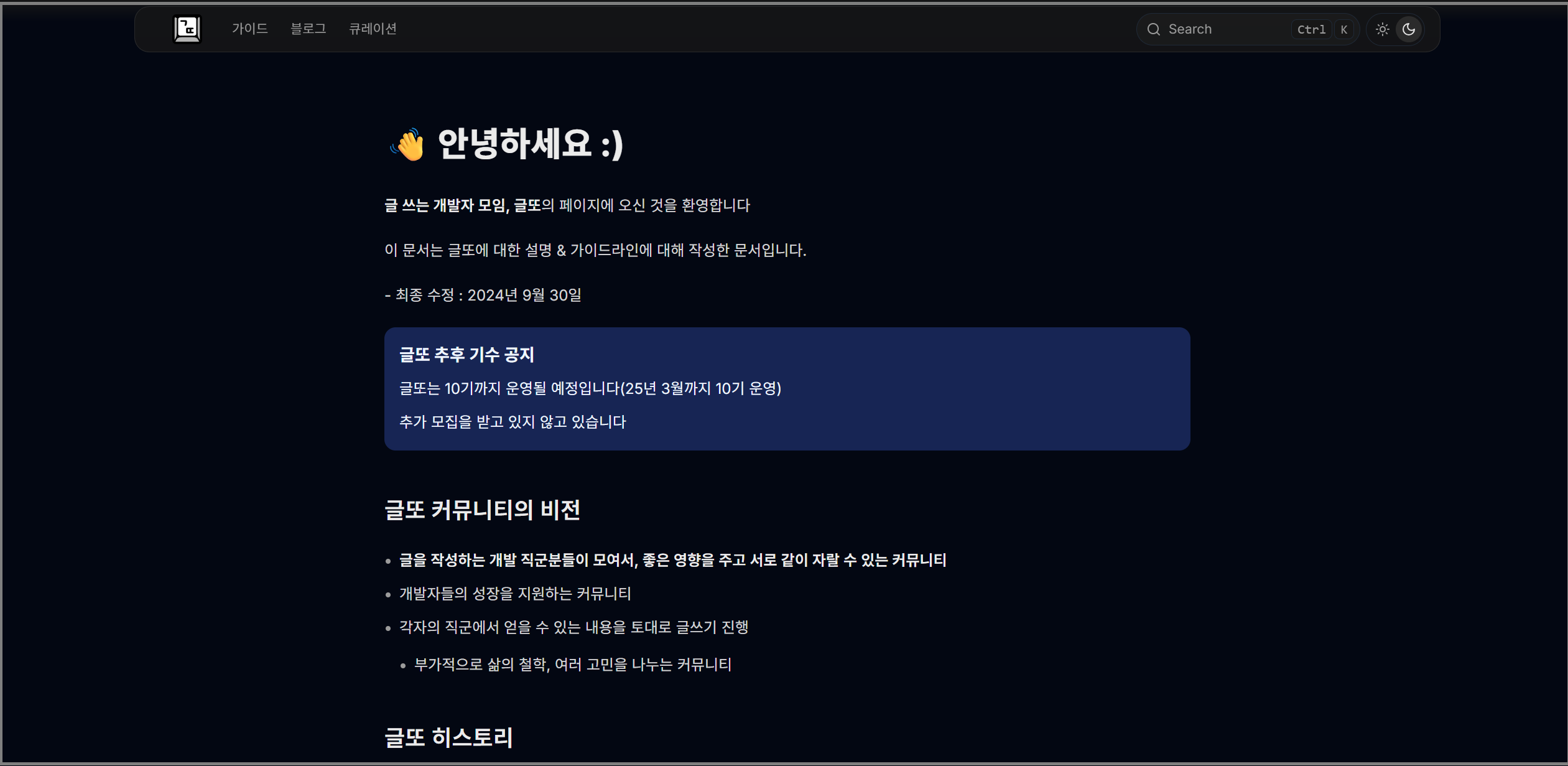
여기서 필자는 상단 네비게이션 부분의 큐레이션으로 들어가면 되지만.. 오른쪽의 검색 부분으로 필자의 수고를 덜하지 않을까 하는 생각에 검색을 해보기로 했다.
근데 여기서 문제가 발생한다.
검색 입력 칸에 글자가 들어가는 순간, 바로 Application Error가 발생한다는 것이다.
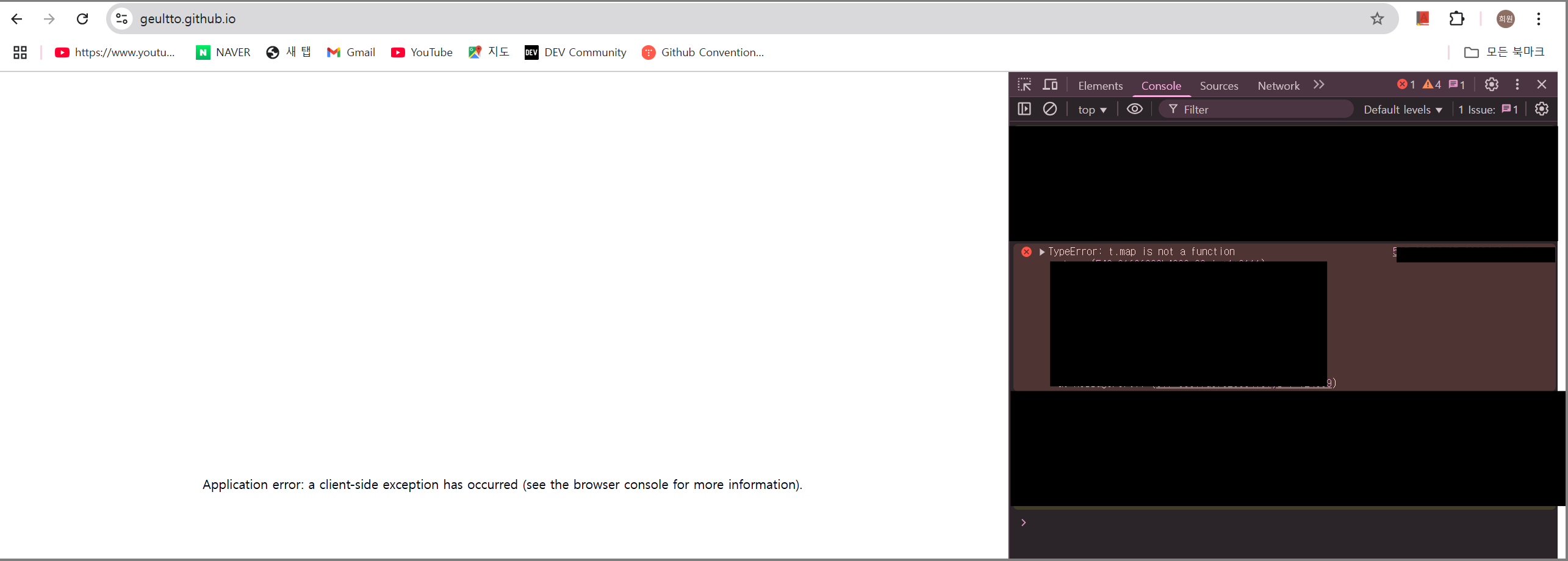
그래서 일단 개발자 도구의 콘솔 부분을 살펴본 결과 다음과 같은 에러가 발생하였다.
TypeError: t.map is not a function
이 에러는 정말 단순하게도 t 자체가 배열이 아니기 때문에, t라는 변수가 .map을 함수로서 사용할 수 없는 에러가 된 것이다.
그래서 일단 이 t의 정체를 알고 싶어서 해당 블로그의 깃허브 저장소를 들어가보았다.
하지만 검색과 관련한 컴포넌트는 app디렉토리 코드에 api/search가 있지만, 이를 활용한다고 명시하는 코드는 src까지 찾아봤지만 없었다.
오.. 이거 쉽게 커뮤니티 및 오픈소스에 기여 할 방법이겠구나
하는 생각이 들어 바로 커뮤니티 내에 질문을 남겼다.

그랬더니 흔쾌히 블로그 운영을 담당해주시는 분 께서 PR을 허락해주셨고, 어떻게 기여 해야하는지, 해당 깃허브 저장소의 마크다운 문서에 따라서 진행해보았다.
지금은 merge되었습니다.
검색기능 그냥 공식문서 참고해서 넣으면 되는 것 아니냐?
괄호()안에 있는 숫자는 개발 시작할 때 부터 대략적인 시간을 나타낸 것입니다.
버전따위는 상관없다(~4)
처음엔 필자는 공식문서를 참고하여 구현하면 되겠다 생각했다.
그러나 여기서 문제가 발생하는데..
필자가 기여하려는 블로그 사이트에서는 fumadocs라는 프레임워크를 사용 중며, 이 프레임워크의 버전은 14.7.0이였다.
그리고 공식문서 사이트에서는 가장 최근 버전인 15.5.1을 기준으로 설명한다는 것이다.
이 버전 차이가 얼마나 차이가 나는지 당장 코드로 비교해보면 다음과 같다.
서버(app/api/search/route.ts)는 기존 코드와 비슷하지만, 클라이언트 단에서 매우 다른 코드를 보여준다.
// 15.5.1 (공식문서 i18n제외)
'use client'
import { useDocsSearch } from 'fumadocs-core/search/client'
import {
SearchDialog,
SearchDialogClose,
SearchDialogContent,
SearchDialogHeader,
SearchDialogIcon,
SearchDialogInput,
SearchDialogList,
SearchDialogOverlay,
type SharedProps,
} from 'fumadocs-ui/components/dialog/search'
export default function DefaultSearchDialog(props: SharedProps) {
const { search, setSearch, query } = useDocsSearch({
type: 'fetch',
})
return (
<SearchDialog
search={search}
onSearchChange={setSearch}
isLoading={query.isLoading}
{...props}
>
<SearchDialogOverlay />
<SearchDialogContent>
<SearchDialogHeader>
<SearchDialogIcon />
<SearchDialogInput />
<SearchDialogClose />
</SearchDialogHeader>
<SearchDialogList items={query.data !== 'empty' ? query.data : null} />
</SearchDialogContent>
</SearchDialog>
)
}
//14.7.0(실제 merge된 파일 중 하나)
'use client'
import React from 'react'
import {
SearchDialog,
type SharedProps,
} from 'fumadocs-ui/components/dialog/search'
import { useDocsSearch } from 'fumadocs-core/search/client'
export default function CustomSearchDialog(
props: SharedProps
): React.ReactElement {
// 검색 설정 - 서버에서 모든 검색 로직 처리
const { query, search, setSearch } = useDocsSearch({
type: 'static',
})
function handleSearchChange(rawQuery: string) {
// 앞뒤 공백만 제거하고 서버에 그대로 전달
setSearch(rawQuery)
}
// 서버 결과를 그대로 사용 (클라이언트 사이드 필터링 제거)
const processedResults = React.useMemo(() => {
// 로딩 중이거나 검색어가 없으면 빈 배열
if (query.isLoading || !search.trim()) {
return []
}
// 에러가 있으면 빈 배열
if (query.error) {
return []
}
// 결과가 'empty'이거나 배열이 아니면 빈 배열
if (query.data === 'empty' || !Array.isArray(query.data)) {
return []
}
// 서버에서 받은 결과를 그대로 반환
return query.data
}, [query.data, query.isLoading, query.error, search])
return (
<SearchDialog
search={search}
onSearchChange={handleSearchChange}
results={processedResults}
{...props}
/>
)
}
당장 클라이언트 파트에서 보면 fumadocs의 버전이 15 버전이 넘어가면서 태그로 세세하게 커스텀 가능하게 변경되는 것을 알 수 있다.
또한 14버전과 15버전의 차이는 지금와서 보면 굉장히 큰 차이인데, 필자는 이 문제를 별거 아닌 문제라 생각하고 왜 공식문서 따라하는데 이런 에러가 발생하는지 머리를 쥐어짜며 4시간을 허비했다.
그렇게 14와 15버전의 차이가 있다는 것을 알게 되고 여기서 더 큰 문제로 빠지게 되는데..
버전을 올려보자(5~8)
14버전이였던 fumadocs를 yarn upgrade로 15버전을 사용하기로 했다.
그러면 공식문서대로 검색을 구현할 수 있겠다는 생각에..
하지만 fumadocs가 14버전에서 15버전으로 발전하면서 tailwind를 4버전만 지원한다고 명시했다.
그렇다면 tailwind도 yarn upgrade로 4버전 업그레이드 하면 될까?
필자는 여기서 부터 뭔가 잘못되었다는 생각이 들었다.
이렇게 된다면, 거의 모든 의존성들을 업그레이드하고, 그로 인해, 검색 부분만 적용한다는 것을 아예 대부분의 파일을 건드리게 될 것이고, 이를 속담으로 표현하자면
빈대 잡느라 초가삼간 다 태운다와 같은 상황이 발생할 것이다.

그렇기 때문에, fumadocs 공식 깃허브 저장소의 공식 문서 커밋 이력을 조회하여 최대한 14.7.0버전과 비슷한 버전의 공식 문서를 살펴보았다.
그 결과, 검색'은' 잘 되는 것으로 확인했다.
한글은 왜 안되는거야(9~12)
다만 여기서 문제가 발생했다. 영어는 매우 잘 되는 것으로 나오지만.. 한글 검색하면 아무것도 뜨지 않는 현상이 발생하는 것이다.
보통 한국의 블로그 글에서는 한글이 가장 많은 비중을 차지함에도, 아무것도 뜨지 않는 현상이 있다는 것은 사실상 검색이 없는 것이나 마찬가지라 생각한다.
그래서 한글이 왜 안되는지.. 먼저 구글링을 해봤지만, fumadocs와 관련하여 다루는 글은 거의 없다시피 하여 gpt와 claude를 번갈아가며 한번 어떻게든 고쳐달라고 요청을 보냈다.
하지만 그들은 fumadocs에게 요청한다는 본질(필자의 의도)을 회피하면서
한글 검색이 가능하게 '보이도록' 사이트 내에서 모든 블로그 텍스트 데이터를 따로 불러오는 코드에 필터링하는 모습을 보여주었고, ui도 영어 검색과 매우 다르게 표시 되어서 의미가 없다는 생각이 들었다.
그래서 이를 어떻게 해결할까 고민하다가 node_modules의 fumadocs의 코드들을 일부 살펴보기로 했다.
만약
import로 사용한 코드의 내부 코드가 궁금하다면 vscode기준,ctrl + click으로 금방 살펴볼 수 있다.
텍스트의 정규화
그렇게 ai에게 내부 코드인 fumadocs파일 중 app/api/search에서 사용 가능한 createFromSource의 내부 코드를 공유하며 같이 살펴보니,
내부 검색 엔진은 orama를 토대로 토큰을 조금 다르게 설정해주면 된다는 것을 알게되었고,
토큰을 수정하여 다음과 같은 코드가 나오게 되었다.
// app/api/search/route.ts
const koreanEnglishTokenizer = {
language: 'ko-en',
normalizationCache: new Map<string, string>(),
tokenize: (text: string) => {
return text
.normalize('NFC')
.split(/[\s.,!?~\-–—()\[\]{}"“”‘’'`:;]+/)
.filter(Boolean)
.map((token) => token.toLowerCase()) // 영어 소문자화 추가
},
}
이를 통해 공식문서에는 없는 한국어를 유니코드로 반환하여 맞는 텍스트를 찾아주는 검색 기능이 만들어졌다.
여기서 위의 코드를 보자면, tokenize부분을 주목해야하는데, .normalize("NFC")를 통해 만약 한글을 입력하면 기존(NFD)처럼 'ㄱㅏ' 가 아닌 '가'로 조합식으로 인식하게 된다.
NFD와 NFC의 차이 표
| 항목 | NFC (Normalization Form Composed) | NFD (Normalization Form Decomposed) |
|---|---|---|
| 뜻 | 조합된 문자로 정규화 (완성형) | 분해된 문자로 정규화 (조합형) |
| 처리 방식 | 가능한 경우, 단일 코드포인트로 합침 | 가능한 경우, 여러 코드포인트로 분리 |
예: 가 | U+AC00 (가 단일 문자) | U+1100 + U+1161 (ㄱ + ㅏ) |
| 사용 용도 | 실제 텍스트 저장/표현, 검색에 적합 | 텍스트 정렬, 문자 분석 등 내부 처리용 |
| 시각적 차이 | 없음 (보기에 동일) | 없음 (보기에 동일) |
| 일반 텍스트 입력기 출력 | 대부분 NFC로 출력 | 거의 사용되지 않음 |
| 주요 사용처 | 웹 텍스트, 파일 저장, DB, 검색엔진 | 유니코드 내부 정렬, 정밀한 NLP |
그래서 normalize(정규화) 중 NFC가 한글에서는 필요하다.
그렇게 적용한 결과, 다음과 같이 정상적으로 검색 기능이 동작하는 것을 확인하게 되었다.
PR 올리기
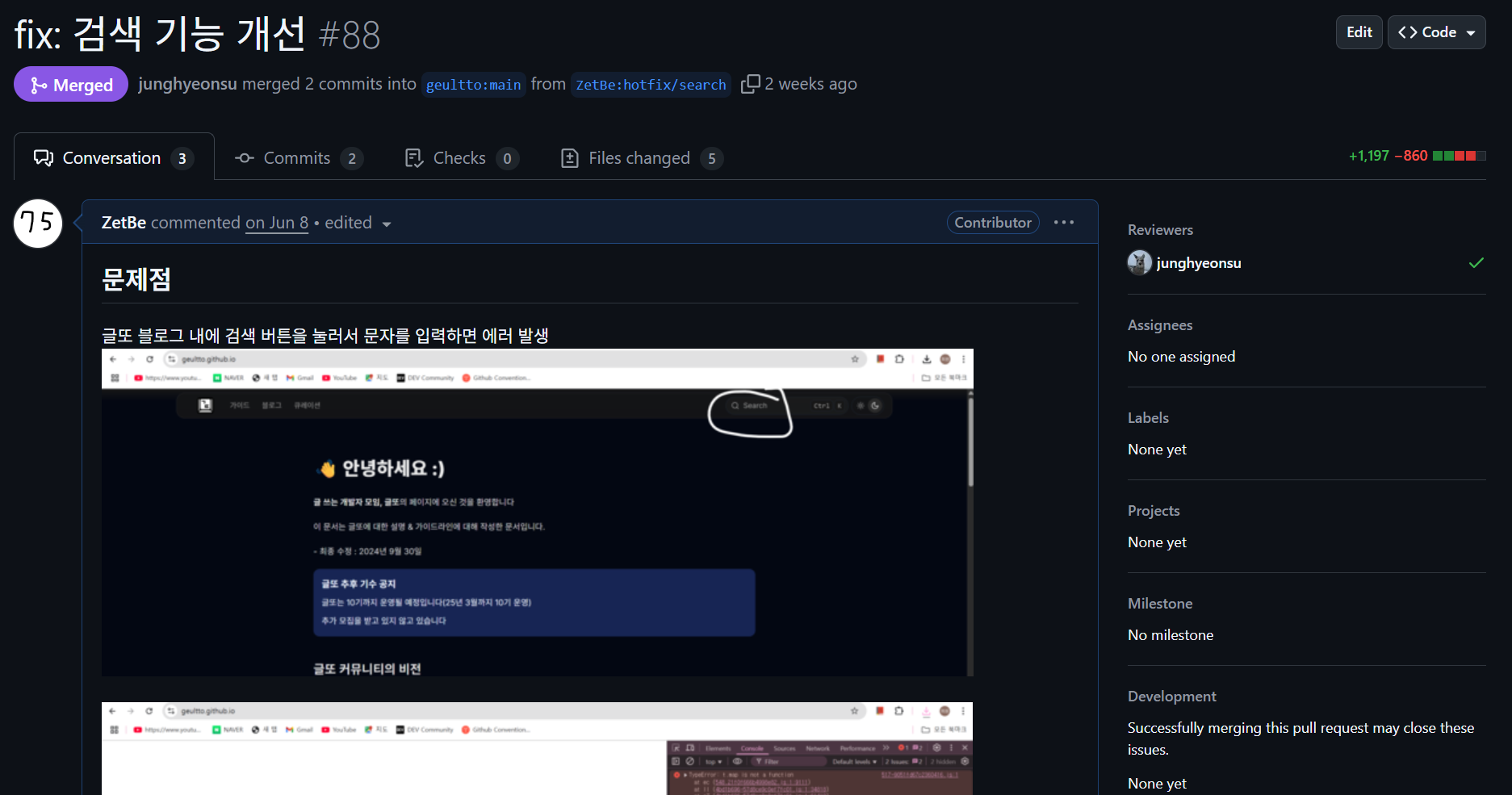
그렇게 필자는 글또 블로그 깃허브에 PR을 올리며 한가지 수정하게 된 사실에 대해 질문을 남겼다.
입력창에서 문자하나 이상입력할 때 부터 서버에 동적으로 요청보내는 부분들이 있어서, next.config.mjs에서 output: "export"를 제거하였는데, 문제없을까요?
이에 대해 블로그 담당 하시던 분 께서 다음과 같은 답변을 남겨 또 문제 해결 과정을 거쳐야하나 걱정이 들었지만,
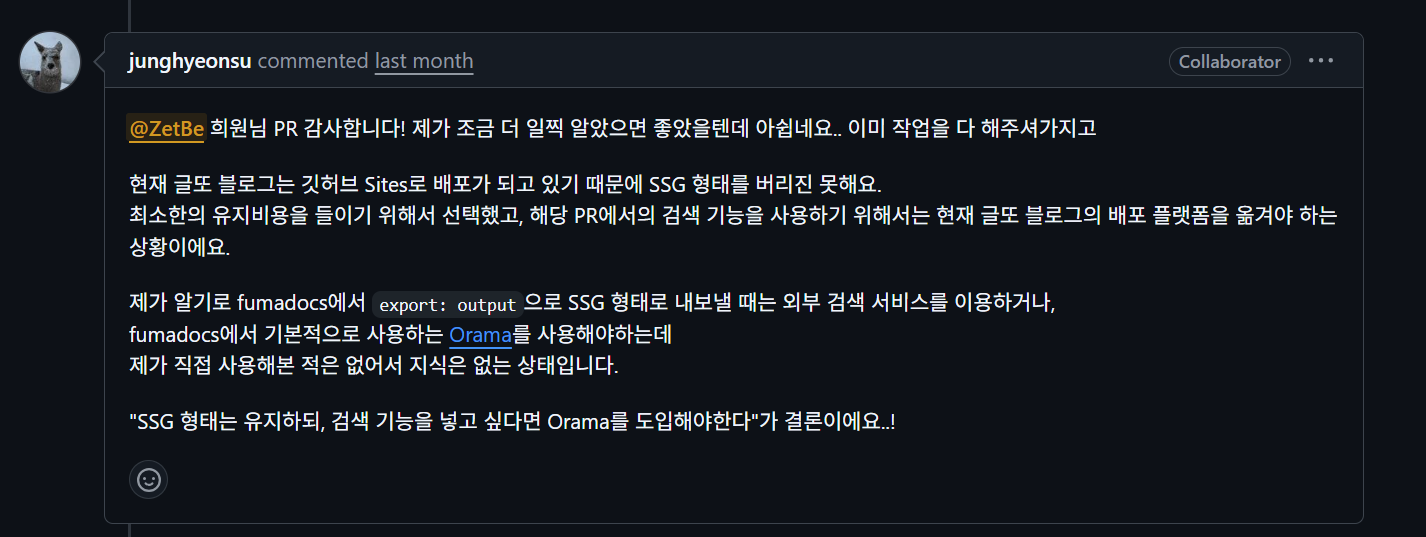
다행히도, 정적 검색을 fumadocs에서 지원해주었기 때문에, 다음과 같이 3개의 파일에 간단히 코드를 수정하여
빌드 시 SSG 형식의 렌더링이 적용되는 것을 확인하였다.
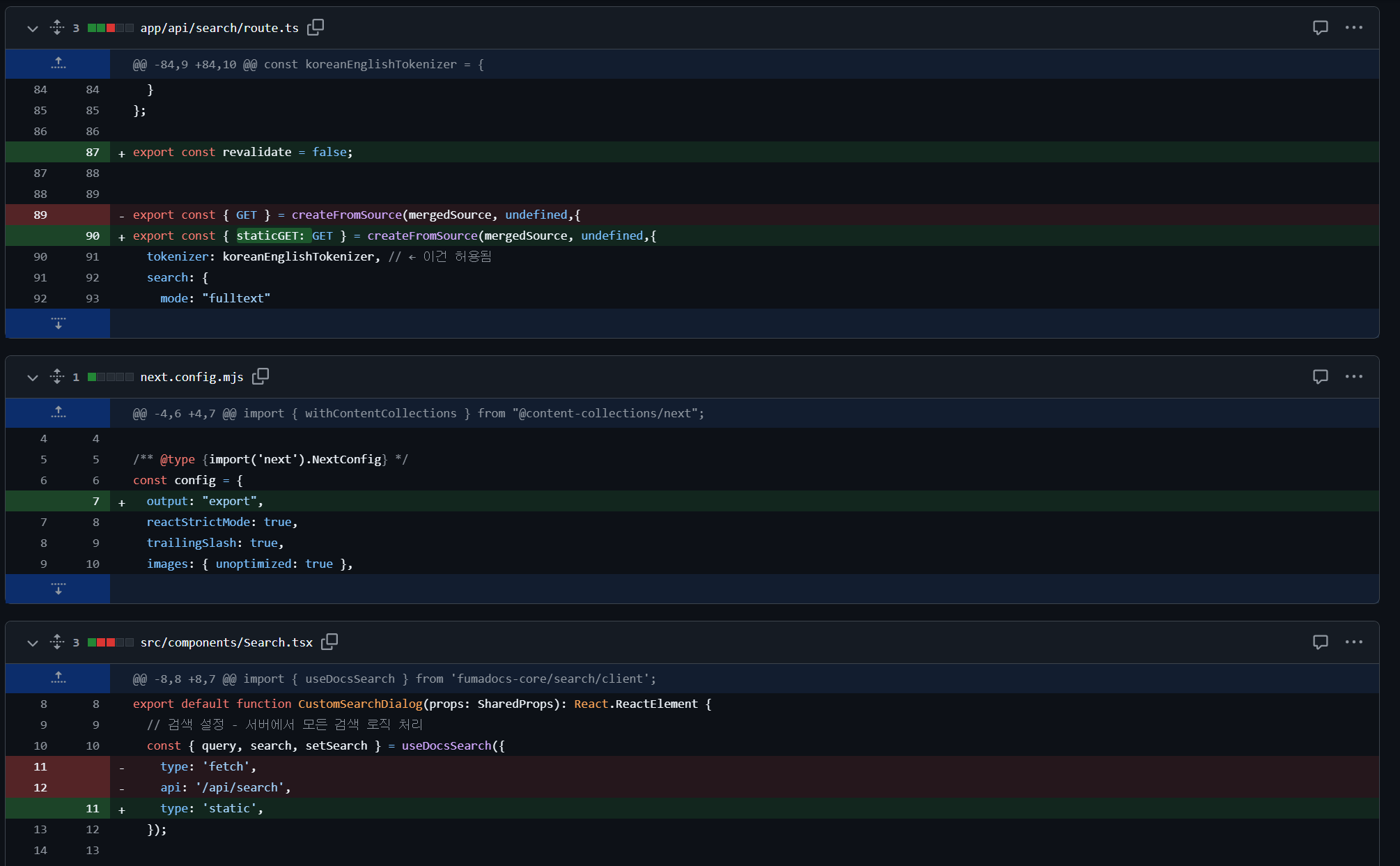
그렇게 필자의 PR은 잘 병합되어 해당 저장소에 기여하는 모습을 볼 수 있다.
마무리
이렇게 해서 2025년 6월 첫 번째 주말을 날리며 다음과 같은 배움을 얻게 되었다.
- 의존성들의 버전을 쉽게 올리지 않는 이유
- (오픈소스로 풀려 있다는 가정 하에 공식문서)특정 버전과 가장 비슷한 날짜의 커밋 이력 찾기
- 내가
import해서 사용하는 변수, 함수 등이 어떤 인자를 받고 내보내는 지, 그리고 어떻게 동작을 하는 지 알아보는 방법 - ai가 알려주는 지식과 짜주는 코드를 너무 믿지 말기
솔직히 필자는 글을 처음 쓸 때, 오픈소스에 기여했어요^^ 같은 식으로 기록을 남기고자 했지만, 예상보다 작업 시간이 너무 길어지면서 글을 쓰는 방향을 다시 바꾸게 되었고,
이런 글이 실제 필자처럼 코딩 중 ai도 딴소리를 하며 헤매는 경우, 혹은 절대적으로 구글링하는데 정보량이 적은 경우 많은 도움이 되었으면 좋겠다.